Lambda表达式
语法:
(param)-> expression 或 (param)->{statements;}
特征:
- 可选类型声明:不需要声明参数类型,编译器可统一识别参数值;
- 可选的参数圆括号:一个参数无需定义(),但多个参数需要定义;
- 可选的大括号:如果主体包含了一个语句,就不需要大括号;
- 可选的返回关键字:如果主体只有一个表达式单回值则编译器会自动返回值,大括号需要指定表达式返回一个数值。
@FunctionalInterface
****修饰函数式接口的注解,要求接口中抽象方法只有一个,和lambda表达式结合使用。
使用:
- 创建函数式接口并使用**@FunctionalInterface**注解;
- 在方法中引用该注解使用;
/**
* @ProjectName: ssm-framework
* @Package: learn.com.jdk.lambda
* @ClassName: ReturnMultiParam
* @Author: zd
* @Description: 多参有返回
* @Date: 2021/9/16 10:46
* @Version: 1.0
*/
@FunctionalInterface
public interface ReturnMultiParam {
String method(int a, String b);
}
public static void main(String[] args) {
//多参有返回
ReturnMultiParam returnMultiParam = (a,b) -> a+b;
System.out.println("ReturnMultiParam:"+returnMultiParam.method(2, "3"));
}Stream流
特性
- Stream流不是一种数据接口,不保存数据,只是在原数据集上定义了一组操作。
- 这些操作每当访问到流中的一个元素,才会在层次元素上执行这一组操作。
- Sream不保存数据,故每个Stream流只可使用一次。
- 流的操作分为两种:中间操作和终止操作;
中间操作的返回结果都是Stream流,故可以多个中间操作叠加;
终端操作用于返回一个新的集合或值,只能有一个终端操作。
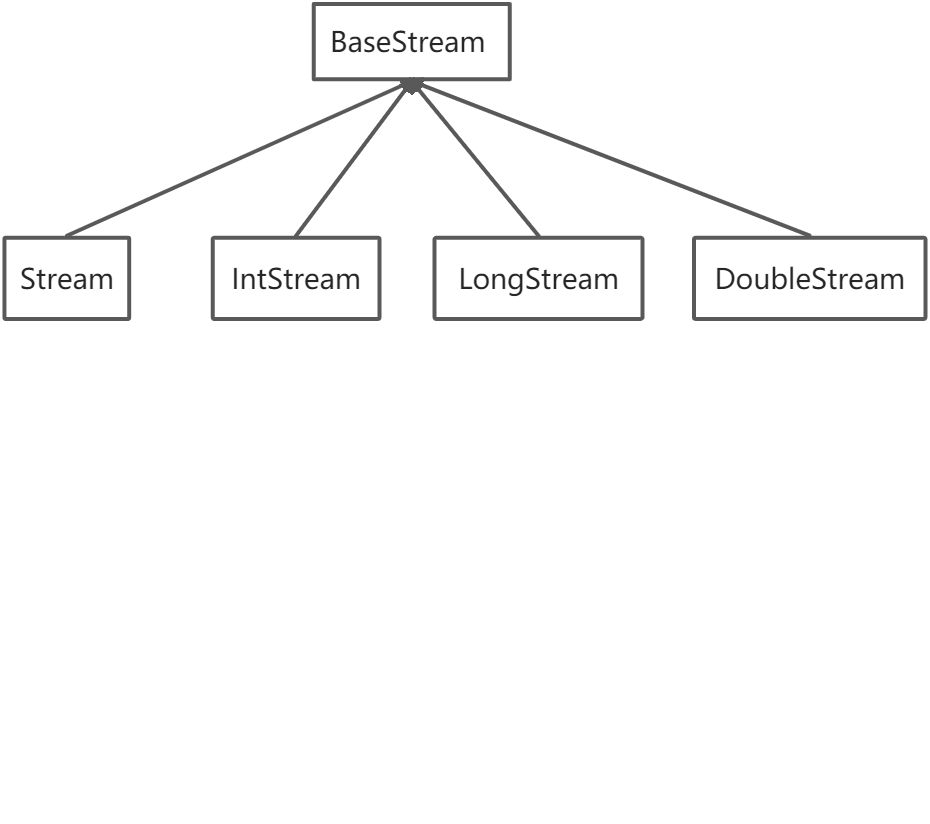
Stream流接口的继承关系:
流的Intermediate方法(中间操作)
filter(T→ boolean)
过滤数据,保留 boolean 为 true 的元素,返回一个集合;
@Test
public void demo3(){
List<String> list =Arrays.asList("a","b","c","ab","ba","abc");
list = list.stream().filter(s -> s.contains("a")).collect(Collectors.toList());
System.out.println(list.toString());
}map(T → R)
转换操作符,可以做数据转换,比如:把字符串转换成int、long、double,或者把一个实体转换成另外一个实体。包含:map,mapToInt、mapToLong、mapToDouble
@Test
public void demo4(){
List<String> list =Arrays.asList("1","2","3");
List<Integer> listInt = new ArrayList<>();
listInt = list.stream().map(s -> Integer.parseInt(s)).collect(Collectors.toList());
System.out.println(listInt.toString());
list.stream().mapToInt(str ->str.length()).forEach(System.out::println);
}flatMap(T → Stream)
将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流
@Test
public void demo5(){
List<List<String>> list = new ArrayList<>();
list.add(Lists.newArrayList("a","b","c"));
list.add(Lists.newArrayList("d","e","f"));
List<String> list1 = list.stream().flatMap(List::stream).collect(Collectors.toList());
System.out.println(list1.toString());
}distinct
去重,类似于msql中的distinct的作用,底层使用了equals方法做比较。
@Test
public void demo6(){
List<String> list = Arrays.asList("a","a","b","c","b");
list=list.stream().distinct().collect(Collectors.toList());
System.out.println(list.toString());
}sorted
对元素进行排序,前提是比较集合中的对象实现Comparable接口重写compareTo方法,或在流中自定义比较器。
@Test
public void demo7(){
List<String> list =Arrays.asList("1","5","3","2");
list = list.stream().sorted().collect(Collectors.toList());
System.out.println(list.toString());
List<String> stringList = Arrays.asList("zd","zc","zb","za");
stringList = stringList.stream().sorted().collect(Collectors.toList());
System.out.println(stringList.toString());
List<User> listUser = new ArrayList<>();
listUser.add(new User().setId(2).setName("张四").setAddress("西安"));
listUser.add(new User().setId(1).setName("张三").setAddress("西安"));
listUser.add(new User().setId(3).setName("张五").setAddress("西安"));
//listUser = listUser.stream().sorted((a,b)->a.getId()- b.getId()).collect(Collectors.toList());
listUser = listUser.stream().sorted((a,b)->a.getName().compareToIgnoreCase(b.getName())).collect(Collectors.toList());
listUser.forEach(user -> System.out.println(user.toString()));
}limit
限流操作,有点类似于mysql中的limit功能,比如:有10个元素,只取前面3个元素.
@Test
public void demo8(){
List<String> list = Lists.newArrayList("1","2","3","4","5");
list = list.stream().limit(3).collect(Collectors.toList());
System.out.println(list.toString());
}skip
跳过操作,比如:有个10个元素,从第5个元素开始去后面的元素
@Test
public void demo9(){
List<String> list = Lists.newArrayList("1","2","3","4","5");
list = list.stream().skip(2).collect(Collectors.toList());
System.out.println(list.toString());
}peek
允许开发者在流的处理过程中对每个元素执行观察或副作用操作,而不会改变流的元素内容。peek()作为中间操作,需要结合终端操作(如collect(), forEach()等)才能触发流的执行。若仅调用peek()而无终端操作,则不会产生任何输出或效果 。
/**
* 在流的处理过程中对每个元素执行观察或副作用操作 1. 调试与日志记录 2. 更新共享状态 3. 验证与异常处理
*/
public class LambdaPeek {
public static void main(String[] args) {
//1. 调试与日志记录
Stream.of("apple", "banana", "cherry")
.peek(s -> System.out.println("Before filter: " + s))
.filter(s -> s.length() > 5)
.peek(s -> System.out.println("After filter: " + s))
.collect(Collectors.toList());
//2. 更新共享状态
int[] count = {0};
Stream.of("apple", "banana", "cherry")
.peek(s -> { if (s.startsWith("b")) count[0]++; })
.forEach(System.out::println);
System.out.println("Count: " + count[0]); // 输出:Count: 1
//3. 验证与异常处理
IntStream.range(1, 6)
.peek(i -> { if (i == 3) throw new RuntimeException("Invalid value"); })
.sum();
}
}流的Terminal方法(终结操作)
forEach
forEach:支持并行处理
forEachOrdered:是按顺序处理的,遍历速度较慢
collect
收集操作,将所有的元素收集起来,Collectors 提供了非常多收集器。包含:toMap、toSet、toList、joining,groupingBy,maxBy,minBy等操作。
toMap:将数据流转换为map,里面包含的元素是用key/value的形式的
List<User> listUser = new ArrayList<>();
listUser.add(new User().setId(2).setName("张四").setAddress("西安"));
listUser.add(new User().setId(1).setName("张三").setAddress("西安"));
listUser.add(new User().setId(3).setName("张五").setAddress("西安"));
Map<Integer, String> collect1=listUser.stream().collect(Collectors.toMap(User::getId, User::getName));toSet:将数据流转换为set,里面包含的元素不可重复
toList:将数据流转出为list,里面包含的元素是有序的
joining:拼接字符串
String collect2=list.stream().collect(Collectors.joining(","));
System.out.println(collect2);
List<String> stringList =Lists.newArrayList("1","2","3");
System.out.println(StringUtils.join(stringList, ","));groupingBy:分组,可以将list转换map
Map<String, List<User>> collect3=listUser.stream().collect(Collectors.groupingBy(User::getAddress));couting:统计元素数量
maxBy:获取最大元素
minBy:获取最小元素
summarizingInt: 汇总int类型的元素,返回IntSummaryStatistics,再调用具体的方法对元素进行统计:getCount(统计数量),getSum(求和),getMin(获取最小值),getMax(获取最大值),getAverage(获取平均值)
List<String> list = Lists.newArrayList("1","11","3","4","9","6");
long count=list.stream().collect(Collectors.summarizingInt(x -> Integer.parseInt(x))).getCount();
System.out.println(count);summarizingLong:汇总long类型的元素,用法同summarizingInt
summarizingDouble:汇总double类型的元素,用法同summarizingInt
averagingInt:获取int类型的元素的平均值,返回一个double类型的数据
List<String> list = Lists.newArrayList("1","11","3","4","9","6");
Double collect5=list.stream().collect(Collectors.averagingInt(value -> Integer.parseInt(value)));
System.out.println(collect5);averagingLong:获取long类型的元素的平均值,用法同averagingInt
averagingDouble:获取double类型的元素的平均值,用法同averagingInt
mapping:获取映射,可以将原始元素的一部分内容作为一个新元素返回
listUser.stream().collect(Collectors.toMap(User::getId,e->e,(a,b)->a));find
查找操作,包含:findFirst、findAny
findFirst:找到第一个,返回的类型为Optional
findAny:使用 stream() 时找到的是第一个元素,使用 parallelStream() 并行时找到的是其中一个元素,返回的类型为Optional
String s=list.stream().findFirst().orElse(null);
System.out.println(s);
String s1=list.parallelStream().findAny().orElse(null);
System.out.println(s1);match
匹配操作,包含:allMatch、anyMatch、noneMatch
allMatch:所有元素都满足条件,返回boolean类型
anyMatch:任意一个元素满足条件,返回boolean类型
noneMatch:所有元素都不满足条件,返回boolean类型
boolean b=listUser.stream().allMatch(user -> user.getId() == 1);
boolean b1=listUser.stream().anyMatch(user -> user.getId() == 1);
boolean b2=listUser.stream().noneMatch(user -> user.getId() == 11);min、max
min:获取最小值,返回Optional类型的数据
max:获取最大值,返回Optional类型的数据
@Test
public void demo12(){
List<Integer> list = Arrays.asList(1,4,2,3);
Optional<Integer> max=list.stream().max((a, b) -> a.compareTo(b));
System.out.println(max.get());
Optional<Integer> min=list.stream().min((a, b) -> a.compareTo(b));
System.out.println(min.get());
}reduce
规约操作,将整个数据流的值规约为一个值,count、min、max底层就是使用reduce。
reduce 操作可以实现从Stream中生成一个值,其生成的值不是随意的,而是根据指定的计算模型。
@Test
public void testReduce() {
List<Integer> list = Lists.newArrayList(2, 3, 5, 7);
Integer sum1 = list.stream().reduce(0, Integer::sum);
//结果:17
System.out.println(sum1);
Optional<Integer> reduce = list.stream().reduce((a, b) -> a + b);
//结果:17
System.out.println(reduce.get());
Integer max = list.stream().reduce(0, Integer::max);
//结果:7
System.out.println(max);
Integer min = list.stream().reduce(0, Integer::min);
//结果:0
System.out.println(min);
Optional<Integer> reduce1 = list.stream().reduce((a, b) -> a > b ? b : a);
//2
System.out.println(reduce1.get());
}toArray
数组操作,将数据流的元素转换成数组。
@Test
public void demo13(){
List<Integer> list = Lists.newArrayList(1,4,2,3);
String[] objects=list.stream().map(integer -> integer.toString()).toArray(String[]::new);
for (String object : objects) {
System.out.println(object);
}
}stream和parallelStream的区别 stream:是单管道,称其为流,其主要用于集合的逻辑处理。
parallelStream:是多管道,提供了流的并行处理,它是Stream的另一重要特性,其底层使用Fork/Join框架实现
/**
* 从两个集合中找相同的元素。
* 一般用于批量数据导入的场景,先查询出数据,再批量新增或修改。
*/
@Test
public void testDemo1(){
List<String> listA=Arrays.asList("1", "2", "4", "6");
List<String> listB=Arrays.asList("1", "2", "7");
List<String> listC=listA.stream().filter(a -> listB.stream().anyMatch(b -> a.equals(b))).collect(Collectors.toList());
System.out.println(listC.toString());
}
/**
* 有两个集合a和b,过滤出集合a中有,但是集合b中没有的元素。
* 这种情况可以使用在假如指定一个id集合,根据id集合从数据库中查询出数据集合,
* 再根据id集合过滤出数据集合中不存在的id,这些id就是需要新增的。
*/
@Test
public void testDemo2(){
List<Integer> listId = Arrays.asList(1,2,3);
List<User> listUser = Arrays.asList(
new User().setId(1).setName("张三").setAddress("西安"),
new User().setId(2).setName("张四").setAddress("延安"),
new User().setId(3).setName("张五").setAddress("渭南"),
new User().setId(4).setName("张六").setAddress("临潼")
);
List<User> userList=listUser.stream().filter(user -> listId.stream().noneMatch(id -> id == user.getId())).collect(Collectors.toList());
System.out.println(userList.toString());
}
/**
* 根据条件过滤数据,并且去重做数据转换
*/
@Test
public void testDemo3(){
List<User> listUser = Arrays.asList(
new User().setId(1).setName("张三").setAddress("西安"),
new User().setId(2).setName("张四").setAddress("延安"),
new User().setId(2).setName("张四").setAddress("延安"),
new User().setId(3).setName("张五").setAddress("渭南"),
new User().setId(4).setName("张六").setAddress("临潼")
);
List<String> list=listUser.stream().filter(user -> !user.getAddress().equals("西安")).map(User::getName).distinct()
.collect(Collectors.toList());
System.out.println(list.toString());
}
/**
* 统计指定集合中,姓名相同的人中年龄最小的id
*/
@Test
public void testDemo4(){
List<User> listUser = Arrays.asList(
new User().setId(1).setName("张三").setAddress("西安"),
new User().setId(1).setName("张四").setAddress("延安"),
new User().setId(2).setName("张四").setAddress("延安"),
new User().setId(3).setName("张四").setAddress("渭南"),
new User().setId(4).setName("张六").setAddress("临潼")
);
listUser.stream().collect(Collectors.groupingBy(User::getName)).forEach((name,list)->{
User user=list.stream().collect(Collectors.minBy((a, b) -> a.getId() > b.getId() ? 1 : 0)).get();
System.out.println(user);
});
}常用函数式接口
Function<T, R>
Function<T, R> 是一个功能转换型的接口,可以把将一种类型的数据转化为另外一种类型的数据
/**
* lambda函数接口 接受一个输入参数,返回一个输出参数
* Function<T, R> 是一个功能转换型的接口,可以把将一种类型的数据转化为另外一种类型的数据
*/
public class LambdaFunction {
public static void main(String[] args) {
//获取每个字符串长度并返回
Function<String, Integer> function = String::length;
Stream<String> stream = Stream.of("张三", "李四", "王五");
Stream<Integer> result = stream.map(function);
result.forEach(System.out::println);
}
}Consumer
<font style="color:rgb(40, 202, 113);">Consumer<T></font>是一个消费性接口,通过传入参数,并且无返回的操作。
Predicate
<font style="color:rgb(40, 202, 113);">Predicate<T></font>是一个判断型接口,并且返回布尔值结果.
Supplier
<font style="color:rgb(40, 202, 113);">Supplier<T></font>是一个供给型接口,无参数,有返回结果。
Optional类
拷贝
将一个对象的属性赋值到另一个对象的情况,这种情况就叫做拷贝
引用拷贝
引用拷贝会生成一个新的对象引用地址,但是两个最终指向依然是同一个对象。当引用对象的属性值发生改变时,被引用对象也会发升改变,内存地址相同,且不重写equals和hashcode方法时也相等。
/**
* 引用拷贝
*/
@Test
public void demo24(){
Demo demo = new Demo("张三",12);
Demo demo1 = demo;
System.out.println(demo);//com.pojo.Demo@61e717c2
System.out.println(demo1);//com.pojo.Demo@61e717c2
demo1.name="李四";
System.out.println(demo1.name);//李四
System.out.println(demo.name);//李四
System.out.println(demo == demo1);//true
}浅拷贝
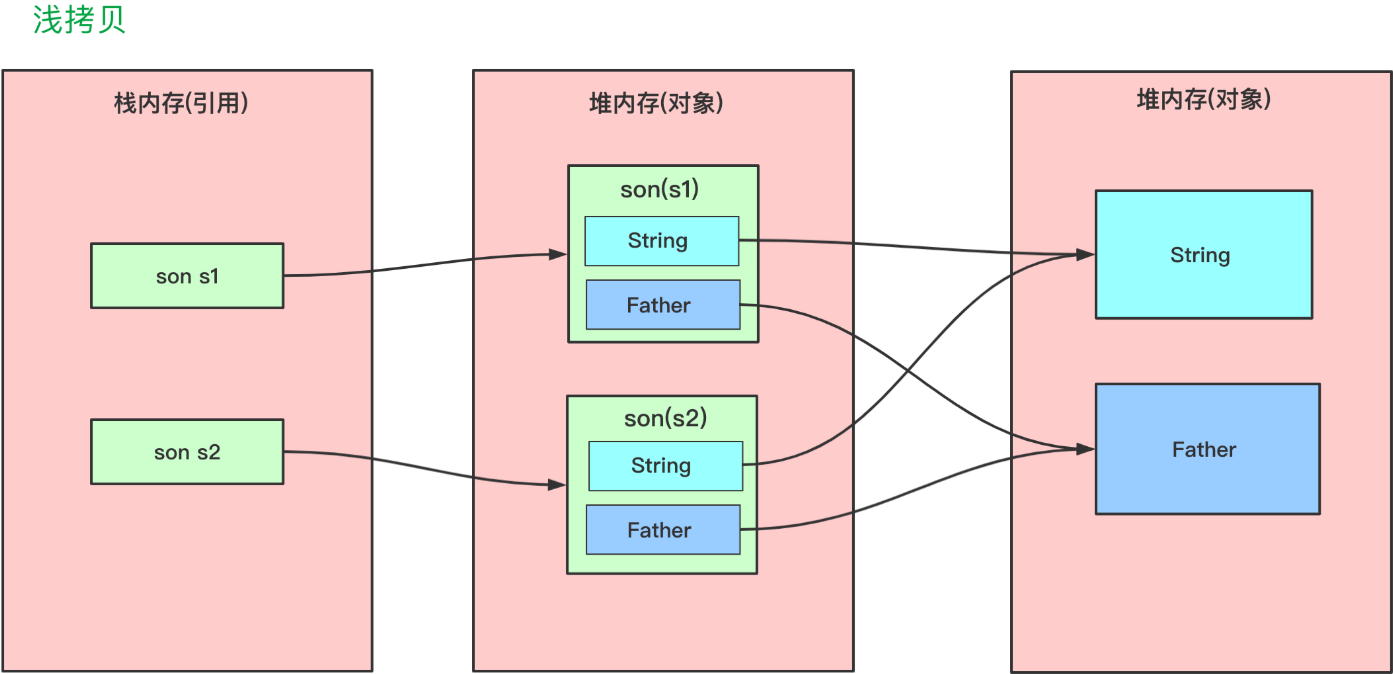
浅拷贝会创建一个新对象,新对象和原对象本身没有任何关系。新对象和原对象不等,但是新对象的属性和老对象相同。
- 如果属性是基本类型(int,double,long,boolean等),拷贝的就是基本类型的值;
- 如果属性是引用类型,拷贝的就是内存地址(即复制引用但不复制引用的对象) ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
/**
* 浅拷贝
*/
@Test
public void demo25() throws CloneNotSupportedException {
Father father = new Father("test");
Son s1 = new Son("s1",12);
s1.father = father;
Son s2=(Son) s1.clone();
System.out.println(s1);
System.out.println(s2);
System.out.println("s1==s2:"+(s1 == s2));//不相等
System.out.println("s1.name==s2.name:"+(s1.name == s2.name));//相等
System.out.println();
//但是他们的Father father 和String name的引用一样
s1.age=12;
s1.father.name="smallFather";//s1.father引用未变
s1.name="son222";//类似 s1.name=new String("son222") 引用发生变化
System.out.println("s1.Father==s2.Father:"+(s1.father == s2.father));//相等
System.out.println("s1.name==s2.name:"+(s1.name == s2.name));//不相等
System.out.println(s1);
System.out.println(s2);
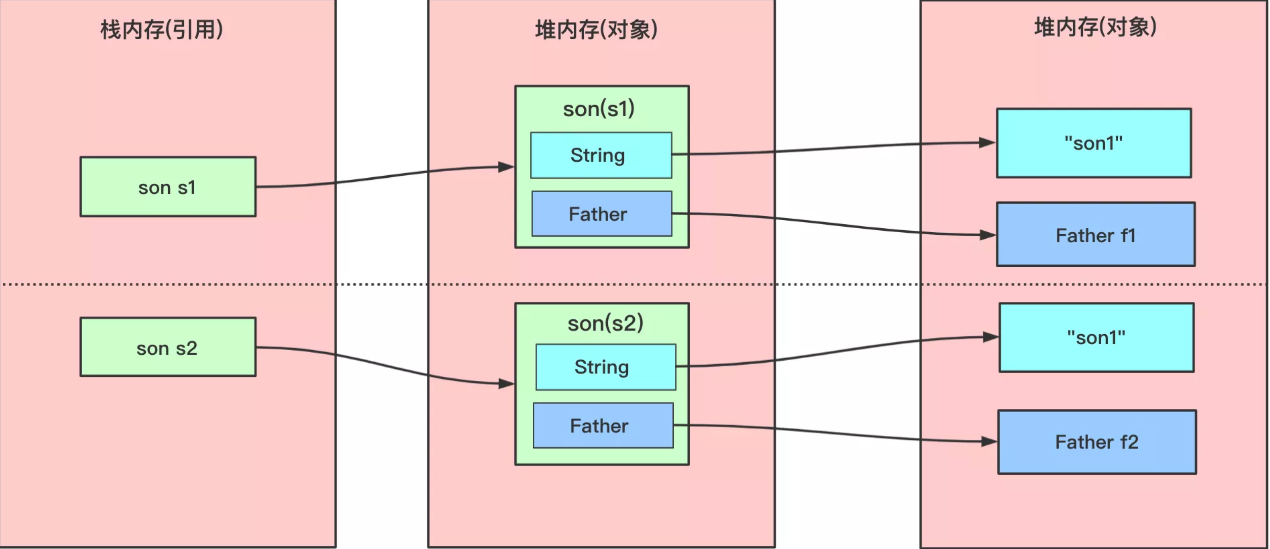
}深拷贝
在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量。
重写clone()方法
如果使用重写clone()方法实现深拷贝,那么要将类中所有自定义引用变量的类也去实现Cloneable接口实现clone()方法。对于字符类可以创建一个新的字符串实现拷贝。
//Father clone()方法
@Override
protected Father clone() throws CloneNotSupportedException {
return (Father) super.clone();
}
//Son clone()方法
@Override
protected Son clone() throws CloneNotSupportedException {
Son son= (Son) super.clone();//待返回拷贝的对象
son.name=new String(name);
son.father=father.clone();
return son;
}方法引用
分类:
| 类型 | 语法 | 对应的Lambda表达式 |
|---|---|---|
| 静态方法引用 | 类名::staticMethod | (args) → 类名.staticMethod(args) |
| 实例方法引用 | inst::instMethod | (args) → inst.instMethod(args) |
| 对象方法引用 | 类名::instMethod | (inst,args) → 类名.instMethod(args) |
| 构建方法引用 | 类名::new | (args) → new 类名(args) |
日期API
新API基于ISO标准⽇历系统,java.time包下的所有类都是不可变类型⽽且线程安全。
| 编号 | 类的名称 | 描述 |
|---|---|---|
| 1 | Instant | 时间戳 |
| 2 | Duration | 持续时间,时间差 |
| 3 | LocalDate | 只包含日期,比如:2018-02-05 |
| 4 | LocalTime | 只包含时间,比如:23:12:10 |
| 5 | LocalDateTime | 包含日期和时间,比如:2018-02-05 23:14:21 |
| 6 | Period | 时间段 |
| 7 | ZoneOffset | 时区偏移量,比如:+8:00 |
| 8 | ZonedDateTime | 带时区的时间 |
| 9 | Clock | 时钟,比如获取目前美国纽约的时间 |
| 10 | java.time.format.DateTimeFormatter | 时间格式化 |
/**
* JAVA8新日期类
*/
public class DateDemo {
public static void main(String[] args) {
//获取今天的日期
LocalDate now = LocalDate.now();
System.out.println("今天的日期:"+now);
System.out.println("-----------------------------");
//获取年、月、日
System.out.println("年:"+now.getYear());
System.out.println("月:"+now.getMonthValue());
System.out.println("日:"+now.getDayOfMonth());
System.out.println("-----------------------------");
//处理特定日期
LocalDate date = LocalDate.of(2018, 10, 10);
System.out.println("特定日期:"+date);
System.out.println("-----------------------------");
//判断两个日期是否相等
LocalDate date1 = LocalDate.of(2018, 10, 10);
LocalDate date2 = LocalDate.now();
System.out.println("两个日期是否相等:"+date1.equals(date2));
System.out.println("-----------------------------");
//判断周期性日期是否一致(月日是否一致判断)
LocalDate localDate = LocalDate.of(1997, 10, 17);
LocalDate localDate1 = LocalDate.of(2025, 10, 17);
MonthDay monthDay = MonthDay.of(localDate.getMonthValue(), localDate.getDayOfMonth());
MonthDay monthDay1 = MonthDay.from(localDate1);
System.out.println("周期性日期是否一致:"+monthDay.equals(monthDay1));
System.out.println("-----------------------------");
//获取当前时间
LocalTime time = LocalTime.now();
System.out.println("获取当前日期,不含日期:"+time);
System.out.println("-----------------------------");
//获取当前时间前后5分钟的时间
LocalTime time1 = LocalTime.now();
LocalTime time2 = time1.plusMinutes(5);
System.out.println("获取当前时间前后5分钟的时间:"+time2);
System.out.println("-----------------------------");
//获取一周后的日期
LocalDate date3 = LocalDate.now();
System.out.println("今天的日期是:"+date3);
LocalDate plus = date3.plus(1, ChronoUnit.WEEKS);
System.out.println("一周后的日期是:"+plus);
System.out.println("-----------------------------");
//计算一年前或一年后的日期
LocalDate date4 = LocalDate.now();
System.out.println("今天的日期是:"+date4);
LocalDate minus = date4.minus(1, ChronoUnit.YEARS);
System.out.println("一年前的日期是:"+minus);
System.out.println("一年后的日期是:"+date4.plus(1, ChronoUnit.YEARS));
System.out.println("-----------------------------");
//Clock时钟类(获取时间戳)
Clock clock = Clock.systemUTC();
System.out.println("时间戳:"+clock.millis());
Clock clock1 = Clock.systemDefaultZone();
System.out.println("时间戳:"+clock1.millis());
System.out.println("-----------------------------");
//比较时间大小
LocalDate now1 = LocalDate.now();
LocalDate now2 = LocalDate.of(2018, 10, 10);
if (now1.isAfter(now2)){
System.out.println("now1比now2晚");
}
if (now1.isBefore(now2)){
System.out.println("now1比now2早");
}
System.out.println("-----------------------------");
//计算两个日期之间的天数
LocalDate date5 = LocalDate.of(2018, 10, 10);
LocalDate date6 = LocalDate.of(2020, 10, 20);
Period between = Period.between(date5, date6);
Period between1 = Period.between(date6, date5);
System.out.println("两个日期之间的天数:"+between.getDays());
System.out.println("两个日期之间的天数:"+between1.getDays());
System.out.println("-----------------------------");
//日期格式化
String format = "20180101";
LocalDate parse = LocalDate.parse(format, DateTimeFormatter.BASIC_ISO_DATE);
System.out.println("日期格式化:"+parse);
System.out.println("-----------------------------");
//字符串日期互转
LocalDate now3 = LocalDate.now();
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
//日期转字符串
String format1 = now3.format(dateTimeFormatter);
System.out.println("日期转字符串:"+format1);
//字符串转日期
DateTimeFormatter dateTimeFormatter1 = DateTimeFormatter.ofPattern("yyyy-MM-dd");
LocalDate parse1 = LocalDate.parse(format1, dateTimeFormatter1);
System.out.println("字符串转日期:"+parse1);
}
}